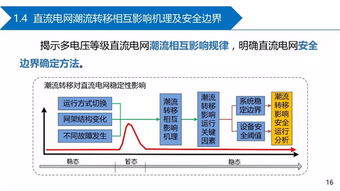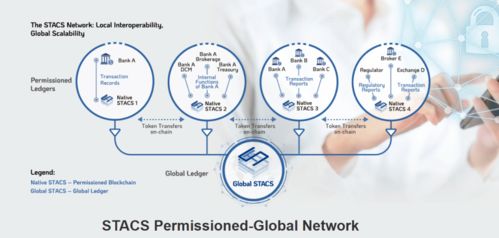
作為中國西部重要的科技與創(chuàng)新中心,成都不僅在傳統(tǒng)互聯(lián)網(wǎng)領(lǐng)域持續(xù)發(fā)力,更在區(qū)塊鏈這一前沿技術(shù)上積極探索,將其融入城市發(fā)展的多個維度,同時推動著底層網(wǎng)絡(luò)技術(shù)的深入研究。
一、成都區(qū)塊鏈技術(shù)的特色應(yīng)用場景
- 政務(wù)服務(wù)與城市治理:成都在“智慧城市”建設(shè)中,利用區(qū)塊鏈不可篡改、可追溯的特性,試點推進(jìn)電子證照、產(chǎn)權(quán)登記、司法存證等領(lǐng)域的應(yīng)用。例如,在政務(wù)服務(wù)大廳,部分業(yè)務(wù)通過區(qū)塊鏈實現(xiàn)數(shù)據(jù)共享與流程優(yōu)化,提升了辦事效率與公信力。
- 數(shù)字文創(chuàng)與版權(quán)保護(hù):依托深厚的文化底蘊(yùn)和活躍的文創(chuàng)產(chǎn)業(yè),成都涌現(xiàn)出利用區(qū)塊鏈進(jìn)行數(shù)字藝術(shù)品確權(quán)、交易和版權(quán)管理的平臺。這為藝術(shù)家和創(chuàng)作者提供了全新的價值實現(xiàn)路徑,也促進(jìn)了本地數(shù)字文創(chuàng)產(chǎn)業(yè)的規(guī)范發(fā)展。
- 供應(yīng)鏈金融與產(chǎn)業(yè)協(xié)同:在成都的制造業(yè)、農(nóng)業(yè)(如特色農(nóng)產(chǎn)品)等領(lǐng)域,區(qū)塊鏈技術(shù)被用于構(gòu)建透明的供應(yīng)鏈體系。通過記錄從生產(chǎn)到銷售的全鏈條信息,幫助企業(yè)增信,并便利了金融機(jī)構(gòu)提供更高效的供應(yīng)鏈金融服務(wù),緩解中小企業(yè)融資難題。
- 醫(yī)療健康數(shù)據(jù)管理:成都的醫(yī)療科研機(jī)構(gòu)與科技公司合作,探索基于區(qū)塊鏈的醫(yī)療數(shù)據(jù)安全共享模式。在保障患者隱私和數(shù)據(jù)安全的前提下,促進(jìn)跨機(jī)構(gòu)醫(yī)療數(shù)據(jù)的可信流轉(zhuǎn),為精準(zhǔn)醫(yī)療和醫(yī)學(xué)研究提供支持。
二、成都區(qū)塊鏈網(wǎng)絡(luò)技術(shù)的研究與創(chuàng)新
區(qū)塊鏈的應(yīng)用落地,離不開底層網(wǎng)絡(luò)技術(shù)的堅實支撐。成都的高校、科研院所和高科技企業(yè)在此領(lǐng)域也展開了富有成效的研究:
- 共識算法與性能優(yōu)化:針對區(qū)塊鏈交易處理速度(TPS)和擴(kuò)展性瓶頸,本地研究團(tuán)隊致力于改進(jìn)共識機(jī)制(如對DPoS、PBFT等算法的優(yōu)化研究),并探索分片、狀態(tài)通道等二層擴(kuò)容方案在具體場景中的適用性,旨在提升網(wǎng)絡(luò)整體性能。
- 跨鏈與互操作性技術(shù):隨著不同區(qū)塊鏈系統(tǒng)的增多,“信息孤島”問題顯現(xiàn)。成都的研究力量關(guān)注跨鏈通信協(xié)議與互操作技術(shù),旨在實現(xiàn)不同鏈間資產(chǎn)與數(shù)據(jù)的可信交互,構(gòu)建更開放的價值互聯(lián)網(wǎng)生態(tài)。
- 隱私計算與安全防護(hù):結(jié)合零知識證明、安全多方計算等密碼學(xué)前沿,成都的研究者著力于在區(qū)塊鏈上實現(xiàn)數(shù)據(jù)“可用不可見”,平衡透明性與隱私保護(hù)需求。對智能合約安全、網(wǎng)絡(luò)攻擊防御的研究也是重點方向。
- 融合新型網(wǎng)絡(luò)架構(gòu):研究區(qū)塊鏈與5G、物聯(lián)網(wǎng)(IoT)、邊緣計算等新一代網(wǎng)絡(luò)技術(shù)的融合。例如,探索在物聯(lián)網(wǎng)設(shè)備間建立輕量級、高可信的協(xié)作機(jī)制,為成都的智慧物流、工業(yè)互聯(lián)網(wǎng)等產(chǎn)業(yè)應(yīng)用注入新動能。
三、展望與挑戰(zhàn)
成都的區(qū)塊鏈發(fā)展正從概念驗證邁向規(guī)模化應(yīng)用,網(wǎng)絡(luò)技術(shù)研究也持續(xù)深化。機(jī)遇與挑戰(zhàn)并存:一方面,需進(jìn)一步明確監(jiān)管框架,加強(qiáng)核心技術(shù)自主創(chuàng)新,培育復(fù)合型人才;另一方面,應(yīng)鼓勵更多跨行業(yè)、跨領(lǐng)域的“區(qū)塊鏈+”試點,推動技術(shù)標(biāo)準(zhǔn)制定,讓區(qū)塊鏈更好地服務(wù)于實體經(jīng)濟(jì)與城市數(shù)字化轉(zhuǎn)型。
從政務(wù)服務(wù)到文創(chuàng)版權(quán),從供應(yīng)鏈到醫(yī)療健康,區(qū)塊鏈技術(shù)正在蓉城悄然落地生根,而其背后的網(wǎng)絡(luò)技術(shù)研究則為這些應(yīng)用提供了堅實的根基。成都,這座既傳統(tǒng)又現(xiàn)代的城市,正以開放、務(wù)實的姿態(tài),在區(qū)塊鏈的浪潮中書寫著自己的創(chuàng)新故事。